

Les grands modèles de langage (LLM) comme ChatGPT ou Google Gemini font régulièrement la une des médias, mais leur utilisation soulève des inquiétudes quant à la confidentialité et la sécurité des données.
Face à ces préoccupations, de plus en plus d'utilisateurs se tournent vers une alternative : l'exécution de LLM localement sur leurs propres ordinateurs.
Dans cet article, nous allons voir où télécharger des modèles et comment les choisir.
Où télécharger des modèles de langage (LLM) ?
Hugging Face : cette plateforme est une référence incontournable pour ceux qui recherchent des modèles de langage open-source. Hugging Face propose une vaste collection de LLM disponibles aux formats GGML ou GGUF, adaptés à une variété de tâches, telles que la génération de texte, de code informatique, de la traduction et bien d'autres. Les modèles couvrent de nombreuses langues et sont régulièrement mis à jour par une communauté active de développeurs et de chercheurs.
Le site wikia.schneedc.com propose une sélection de modèle.
GGML et GGUF : quelle différence ?
GGML et GGUF sont des formats utilisés pour les modèles de langage large (LLM) en intelligence artificielle. Voici ce qui les distingue :
- GGML (Generalized Generative Model Language) : Ce format est conçu pour être efficace et compatible avec de nombreux systèmes. Il facilite le déploiement de modèles de langage sur diverses plateformes.
- GGUF (Generalized Generative Universal Format) : C'est une version améliorée de GGML. GGUF offre une meilleure performance et une compatibilité accrue en intégrant les dernières avancées technologiques et techniques d'accélération. Cela permet une utilisation plus universelle et optimisée des modèles de langage.
En résumé, GGUF est plus avancé et performant, tandis que GGML reste largement efficace et adaptable.
Choisir un modèle :
En fonction de ses performances :
Pour sélectionner un modèle d'IA de haute qualité, similaire aux plus réputés, vous pouvez consulter les classements de performance sur les sites suivants :
- https://chat.lmsys.org/?leaderboard (vous pouvez filtrer les modèles / bouton Category)
- https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard * (classement sans modèles propriétaires)
- https://openrouter.ai/rankings
- https://llm.extractum.io/list / https://llm.extractum.io/list/?uncensored
- https://www.trustbit.tech/en/llm-benchmarks
- https://oobabooga.github.io/benchmark.html
- https://eqbench.com/ classement LLM par intelligence émotionnelle
- https://gorilla.cs.berkeley.edu/leaderboard.html
- https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard (classement llm non censurés)
Classement chat.lmsys.org fin mai 2024 :
(1) : Attention ! Les modèles propriétaires ne sont pas téléchargeables.
(2) : Le meilleur modèle non propriétaire en mai 2024 est le modèle Llama-3-70b-Instruct. Vous pouvez le télécharger sur le site de Meta ou sur HuggingFace.

* Explication des colonnes de ce classement :
Average : Indique qu'il s'agit d'une moyenne des scores obtenus sur les benchmarks suivants.
ARCHella : Ce benchmark évalue la capacité du modèle à générer des dialogues cohérents et informatifs dans un contexte de chat.
Swag : Ce benchmark évalue la capacité du modèle à répondre à des questions ouvertes de manière complète et informative.
MMLU : Ce benchmark évalue la capacité du modèle à effectuer des tâches de raisonnement et de manipulation de langage.
TruthfulQA : Ce benchmark évalue la capacité du modèle à distinguer les informations vraies des fausses.
Par capacité ou par popularité :
Sur Hugging Face, à la rubrique Models, vous pouvez facilement trouver un modèle en filtrant les résultats selon différents critères :
- Par tâches : utilisez la colonne "tasks" pour sélectionner des modèles en fonction des tâches spécifiques qu'ils peuvent réaliser, comme les résumés, les traductions, ou le traitement en langue française.
- Par popularité ou par nombre de téléchargements : utilisez l'option "Sort" pour afficher les modèles les plus populaires ou les plus téléchargés.
- Par mots-clés : Utilisez la recherche par mots clés pour filtrer les modèles par mots-clés en anglais, comme "role play", "nsfw", etc.
En fonction de l'avis des utilisateurs :
Consultez les avis des utilisateurs du forum Reddit pour lire leur retour d'expérience avec différents modèles.
- Recherche sur le forum : faites une recherche avec des termes comme "best chat LLM" ou "best roleplay and chat LLM", puis lisez les commentaires et discussions pour obtenir des recommandations.
- Recherche avec GigaBrain : Utilisez cet outil pour obtenir un résumé rapide de vos recherches, par exemple en cherchant "best local LLM for chats".
Choisir la version d'un LLM :
Une fois que vous avez choisi un modèle, rendez-vous sur sa page Hugging Face.
Dans la section "Files and versions", vous trouverez plusieurs versions disponibles au téléchargement. Ces versions varient en termes de compression, de taille et d'efficacité. En général, un modèle plus compressé se chargera et s'exécutera plus rapidement, mais avec une précision réduite. Les fichiers sur Hugging Face représentent différents niveaux de compression, allant du plus faible au meilleur.
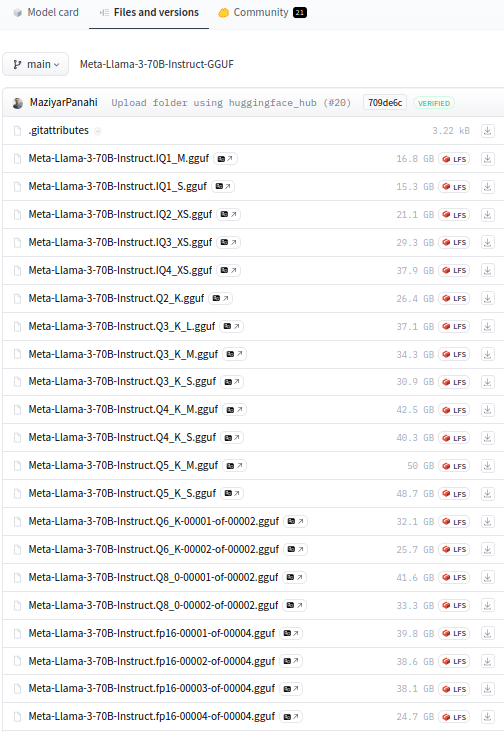
Il est crucial de choisir la version qui correspond le mieux à vos besoins et à votre configuration matérielle.
Par exemple, une version Q4 sera plus petite qu'une version Q5, mais avec une qualité légèrement inférieure. Les versions de fichiers, classées de la plus petite à la plus grande taille (et généralement de la plus faible à la meilleure qualité), sont :
- Q1_M_S
- Q2K
- Q3_K_S
- Q3_K_M
- Q3_K_L
- Q4_0
- Q4_K_S
- Q4_1
- Q4_K_M
- Q5_0
- Q5_1
- Q5_K_S
- Q5_K_M
- Q6_K
- Q8_0
- F16
Attention ! Plus le modèle est volumineux, plus votre ordinateur doit être puissant pour l'exécuter. Par exemple, certains modèles avec 70 milliards de paramètres nécessitent 64 Go de RAM (70B Q4).
Conclusion :
Vous pouvez maintenant exécuter vos modèles en local à l'aide de logiciels comme Ollama, Jan ou KoboldCpp (article à venir). Vous bénéficierez de modèles gratuits et pour certains aussi performants que ceux du marché.
Enregistrer un commentaire
Les commentaires sont validés manuellement avant publication. Il est normal que ceux-ci n'apparaissent pas immédiatement.